容器网络深度解析:从零基础到 Kubernetes
版本:v1.0 阅读前提:不需要任何计算机网络基础。本文从"什么是IP地址"开始,逐步带你理解 Docker 和 Kubernetes 中的网络是如何工作的。
写在最前面:容器网络到底要解决什么问题?
当你执行 docker run 创建一个容器时,Docker 会同时创建一个叫 Network Namespace 的隔离环境。这个 Namespace 相当于给容器颁发了一套"独立的网络身份证"——它有自己的网卡 eth0、自己的 IP 地址、自己的路由表、甚至自己的 127.0.0.1(本地回环)。从容器内部的视角看,它独占了一整套网络栈,完全感知不到宿主机和其他容器的存在。
但隔离只是第一步。容器真正需要回答的问题是:被隔离后的容器,如何与外部世界通信? 具体来说,有三类通信场景必须解决:
| 通信场景 | 问题描述 | 例子 |
|---|---|---|
| 容器 ↔ 宿主机 | 容器怎么访问互联网?宿主机上的浏览器怎么访问容器里的网站? | 容器内 curl baidu.com;浏览器访问 localhost:8080 |
| 容器 ↔ 容器 | 同一台机器上的多个容器怎么互相找到对方? | Web 容器连接数据库容器 |
| 服务发现 | 容器的 IP 是动态分配的,重启后可能变化,如何用稳定的名称找到对方? | 用 db 这个名字代替 172.17.0.2 |
为了彻底理解这些问题的解决方案,我们需要从最基础的网络概念开始。不要跳过接下来的章节——它们是理解容器网络的真正基石。
1. 计算机网络基础速成
1.1 IP 地址与 MAC 地址:网络世界的"门牌号"和"身份证"
想象你住在一栋公寓楼里。快递员要给你送包裹,需要两个信息:你的房间号(精确到你在楼里的位置)和你的身份证号(唯一标识你这个人)。
在网络世界中,IP 地址就是你的"房间号"。它是一个 32 位(IPv4)或 128 位(IPv6)的数字,通常写成四段十进制形式,如 192.168.1.100。IP 地址的作用是在网络中进行路由选择——当数据包要从北京发往上海时,路由器根据目标 IP 地址决定下一跳该往哪走。 (oneuptime.com)
MAC 地址则是你的"身份证号"(更准确地说是"网卡的身份证号")。它是一个 48 位的硬件地址,形如 02:42:ac:11:00:02,由网卡制造商在生产时烧录进去,全球唯一。MAC 地址的作用范围仅限于同一个局域网(同一台交换机覆盖的范围)——交换机根据目标 MAC 地址决定把数据包转发到哪个端口。 (Red Hat Developer)
| 对比项 | IP 地址 | MAC 地址 |
|---|---|---|
| 作用层级 | 网络层(三层) | 数据链路层(二层) |
| 格式 | 192.168.1.100(可变) |
02:42:ac:11:00:02(固定) |
| 作用范围 | 跨网络、全球路由 | 同一局域网内 |
| 类比 | 房间号(可搬家) | 身份证号(终身不变) |
为什么需要两个地址? 因为网络通信是分层进行的。在同一个房间(局域网)里,人们通过身份证号(MAC)直接找到对方;要从一个房间走到另一个房间(跨网络),则需要房间号(IP)来导航。两者缺一不可。
1.2 交换机与网桥:局域网内的"交通警察"
交换机(Switch)是一种工作在二层的网络设备,连接着局域网内的多台设备。它的核心工作方式是学习 MAC 地址:当一台电脑第一次发送数据时,交换机记录下"这个 MAC 地址是从哪个端口进来的"。以后收到发给这个 MAC 地址的数据包,就直接从对应的端口转发出去,不需要广播给所有人。 (Red Hat Developer)
网桥(Bridge)本质上就是软件实现的交换机。Linux 内核提供的 Linux Bridge 功能,允许你在操作系统内部创建一个虚拟交换机。Docker 默认使用的 docker0 就是一个 Linux Bridge。它的行为和物理交换机完全一致:学习 MAC 地址、根据 MAC 地址转发数据包。 (天翼云)
1.3 NAT:让私有 IP 也能上互联网
IP 地址分为两类:公网 IP(全球唯一,可直接访问互联网)和私有 IP(仅在局域网内有效,如 192.168.x.x、172.17.x.x、10.x.x.x)。容器的 IP 地址(如 172.17.0.2)属于私有 IP,互联网上的服务器不认识这个地址,也不会把响应包路由回来。
NAT(Network Address Translation,网络地址转换) 解决了这个问题。NAT 的核心思想是"偷梁换柱":当私有网络的设备要访问互联网时,NAT 设备(通常是路由器或防火墙)把数据包的源 IP 地址从私有 IP 替换为自己的公网 IP;收到响应包后,再根据之前的记录把目标 IP 换回来,转发给正确的内网设备。 (oneuptime.com)
| NAT 类型 | 作用方向 | 通俗解释 |
|---|---|---|
| SNAT(源地址转换) | 内网 → 外网 | “出村时换上村长的衣服”,把容器 IP 换成宿主机 IP |
| DNAT(目标地址转换) | 外网 → 内网 | “进村时按门牌号找人”,把宿主机端口映射到容器端口 |
Docker 默认通过 iptables(Linux 防火墙工具)自动插入 NAT 规则。你不需要手动配置,但这背后的原理必须理解。
1.4 DNS:互联网的"通讯录翻译官"
DNS(Domain Name System)是互联网上最重要的基础设施之一。它的作用可以用一句话概括:把人类能记住的名字翻译成机器能识别的 IP 地址。
当你在浏览器输入 www.baidu.com 时,你的电脑会向 DNS 服务器发起查询:“百度是多少号?” DNS 服务器回答:“是 14.215.177.38"。然后你的电脑才去向这个 IP 地址建立连接。整个过程通常在 100 毫秒内完成,你感知到的只是"网页打开了”。
DNS 查询是一个分层递归的过程:先查本地缓存 → 再查配置的 DNS 服务器(如 8.8.8.8 或 114.114.114.114)→ 如果不知道,继续向上游查询,直到找到权威 DNS 服务器(如百度自己管理的 DNS 服务器)给出最终答案。
在容器网络中,DNS 的作用更加关键。因为容器的 IP 是动态分配的,你不能在代码里写死 IP 地址。Docker 和 Kubernetes 都内置了 DNS 服务,让容器可以通过名字而不是 IP 来找到对方。
2. 容器网络的基石:Network Namespace
2.1 什么是 Network Namespace?
Network Namespace 是 Linux 内核提供的一种网络资源隔离机制。在同一个宿主机上,可以存在多个相互独立的 Network Namespace,每个 Namespace 都有自己的:
- 网络接口(网卡,如
eth0、lo) - IP 地址和路由表
- iptables 防火墙规则
- 套接字(socket)和连接状态
/proc/net目录下的网络统计信息
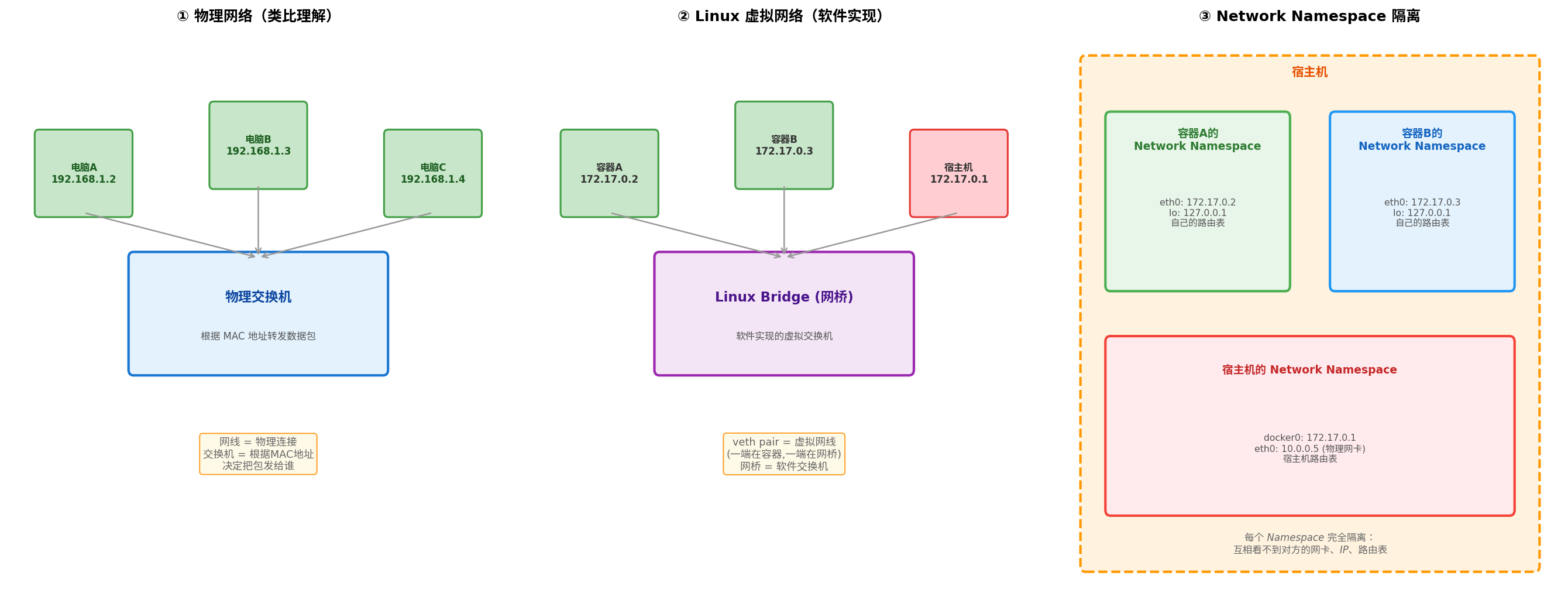
从上图可以清晰地看到演进关系:物理世界中有交换机和网线连接多台电脑;Linux 用 Bridge(软件交换机)和 veth pair(虚拟网线)在软件层面复现了这套机制;而 Network Namespace 则把每个容器的网络环境完全隔离在一个独立的空间中。
2.2 veth pair:连接两个 Namespace 的"虚拟网线"
veth(Virtual Ethernet)是 Linux 提供的一种成对出现的虚拟网络设备。你可以把它想象成一根网线的两端:数据从一端进入,必定从另一端出来。创建 veth pair 的命令如下: (man7.org)
# 创建一对 veth 设备
ip link add veth-host type veth peer name veth-container
# 把一端放入容器的 Namespace
ip link set veth-container netns <container_namespace>
# 另一端留在宿主机,连接到网桥
ip link set veth-host master docker0
Docker 在创建每个容器时,都会自动执行上述操作。容器里的 eth0 就是 veth pair 的一端,宿主机上对应的 vethxxxxx 设备就是另一端。 (oneuptime.com)
3. Docker Bridge 网络详解
3.1 默认 Bridge 网络:docker0
当你安装 Docker 后,宿主机上会自动出现一个虚拟网络设备:
$ ip addr show docker0
3: docker0: <BROADCAST,MULTICAST,UP> mtu 1500
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
docker0 是一个 Linux Bridge(软件网桥),工作在 OSI 第二层(数据链路层)。它的核心行为包括: (Red Hat Developer)
- MAC 地址学习:记录每个端口对应的 MAC 地址
- 二层转发:根据目标 MAC 地址把数据包转发到正确的端口
- 广播泛洪:对于未知目标 MAC 的数据包,向所有端口广播(类似交换机)
- 网关功能:
docker0本身有 IP 地址172.17.0.1,充当容器子网的网关
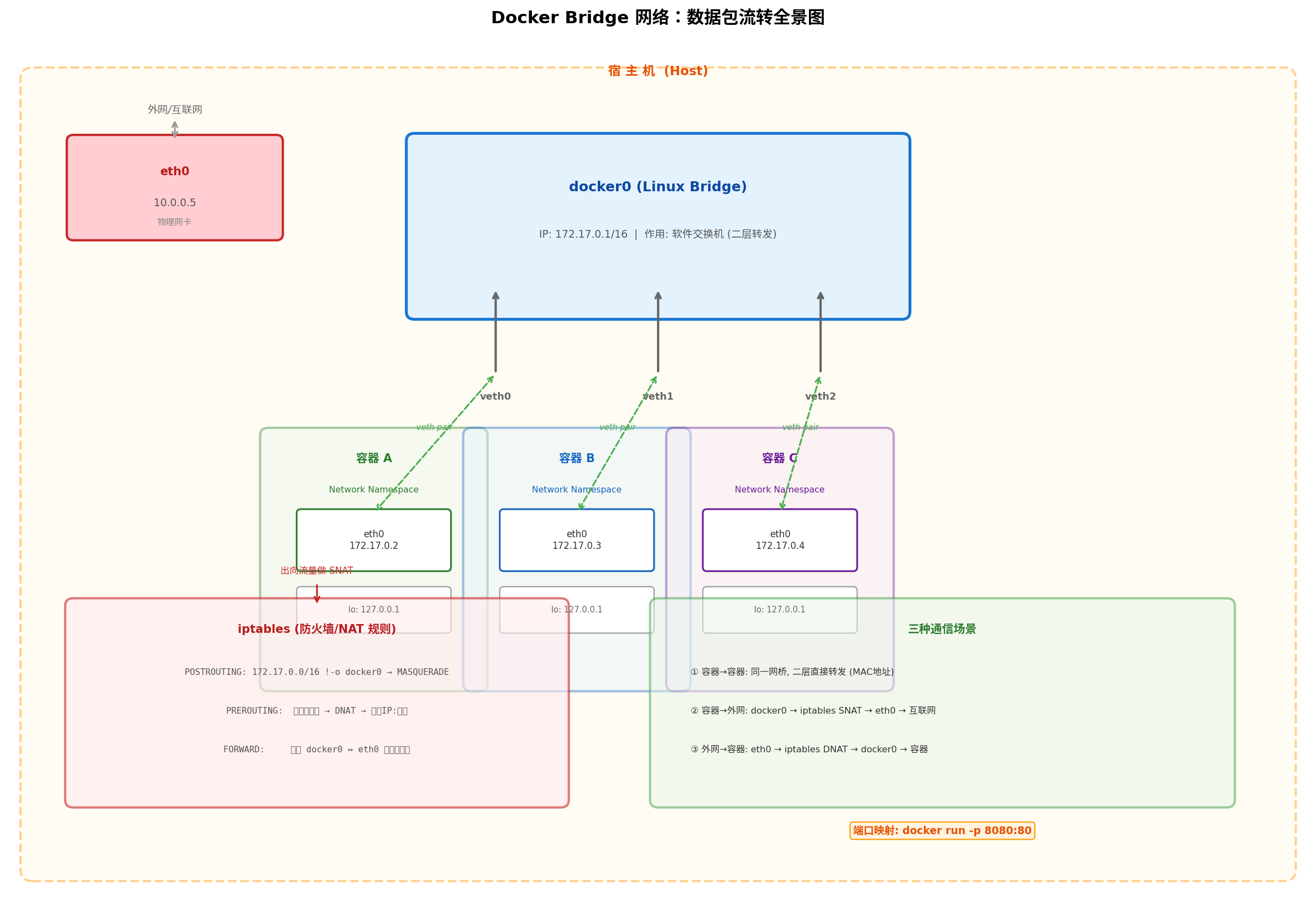
上图展示了 Docker Bridge 网络的完整拓扑:物理网卡 eth0 连接外网,docker0 作为虚拟交换机连接所有容器,veth pair 充当容器与网桥之间的虚拟网线,iptables 负责 NAT 和端口映射。
3.2 容器启动时的网络创建流程
当你执行 docker run -d nginx 时,Docker Daemon 在后台依次完成以下操作: (oneuptime.com)
步骤 1:创建 Network Namespace
Docker 为容器分配一个独立的 Network Namespace。从此,容器拥有自己独立的网络栈。
步骤 2:创建 veth pair
Docker 创建一对 veth 设备。一端命名为 eth0(放入容器的 Namespace),另一端命名为 vethxxxx(留在宿主机)。
步骤 3:连接 veth 到 docker0
将宿主机端的 veth 设备插入 docker0 网桥。此时,容器与网桥之间建立了虚拟连接。
步骤 4:分配 IP 地址和路由
Docker 从 172.17.0.0/16 子网中分配一个空闲 IP(如 172.17.0.2)给容器的 eth0,并设置默认路由指向 docker0(172.17.0.1)。
步骤 5:配置 iptables 规则
Docker 自动插入 iptables NAT 规则,确保容器的出向流量可以被正确转换,入向流量可以被正确转发。
3.3 三种通信场景的完整数据流转
场景 A:容器访问外网(出向流量)
容器内执行 curl baidu.com,数据包的完整旅程如下:
容器(172.17.0.2) → eth0 → veth pair → docker0 → iptables SNAT(MASQUERADE)
→ 宿主机 eth0(10.0.0.5) → 互联网 → 百度服务器
关键步骤——SNAT(源地址转换):容器发出的数据包源 IP 是 172.17.0.2(私有地址),互联网服务器不认识这个地址。Docker 预先配置的 iptables 规则会在数据包离开宿主机前,把源 IP 替换成宿主机的公网 IP(如 10.0.0.5)。这相当于容器"借用"了宿主机的身份上网。
# Docker 自动插入的 SNAT 规则
iptables -t nat -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
回包过程:百度服务器回包给 10.0.0.5。宿主机收到后,根据 conntrack(连接追踪) 记录,知道这是 172.17.0.2 发出去的请求的响应,做 DNAT 把目标 IP 改回 172.17.0.2,通过 docker0 → veth → 容器。 (oneuptime.com)
场景 B:外部访问容器(入向流量,端口映射)
执行 docker run -p 8080:80 nginx,外部用户访问 http://宿主机IP:8080:
外部用户 → 宿主机:8080 → iptables DNAT → 容器:80(172.17.0.2) → Nginx处理
关键步骤——DNAT(目标地址转换):-p 8080:80 的本质是在宿主机上插入一条 iptables 规则:所有访问宿主机 8080 端口的流量,把目标地址改写成容器的 IP 和端口(172.17.0.2:80)。
# Docker 自动插入的 DNAT 规则
iptables -t nat -A PREROUTING -p tcp --dport 8080 -j DNAT --to-destination 172.17.0.2:80
重要认知:-p 8080:80 是在宿主机上开了一个端口,和容器本身没有直接绑定。如果你不写 -p,外部流量无法直接进入容器——这是 Docker 的一层安全设计。 (oneuptime.com)
场景 C:同一宿主机上的容器间通信
容器 A(172.17.0.2)ping 容器 B(172.17.0.3):
- 判断目标在同一子网:
172.17.0.3属于172.17.0.0/16,不需要走网关 - ARP 解析:容器 A 广播 ARP 请求"谁是
172.17.0.3?",docker0将广播泛洪到所有端口。容器 B 收到后回复自己的 MAC 地址 - 二层直接转发:容器 A 拿到容器 B 的 MAC 地址后,构造以太网帧直接发送。
docker0根据 MAC 地址表转发到容器 B 的 veth 端口
全程不经过三层路由,不经过宿主机协议栈,效率非常高。
3.4 默认 Bridge 的局限与自定义 Bridge
默认 docker0 网络有一个关键缺陷:不支持 DNS 服务发现。容器之间只能用 IP 通信,不能用容器名。这意味着如果数据库容器重启后 IP 变了,Web 容器就会连不上。
自定义 Bridge 网络解决了这个问题:
docker network create my-net
docker run --network my-net --name web nginx
docker run --network my-net --name db postgres
自定义 Bridge 网络的改进包括: (quashbugs.com)
| 特性 | 默认 docker0 | 自定义 Bridge |
|---|---|---|
| DNS 服务发现 | ❌ 不支持 | ✅ 内置 DNS,支持容器名解析 |
| 网络隔离 | 所有容器互通 | 可创建多个独立网络 |
| 子网分配 | 固定 172.17.0.0/16 |
自动分配不冲突子网 |
| 热插拔 | 运行中不能切换网络 | 支持动态连接/断开 |
| iptables 规则 | 混在全局链中 | 独立的隔离规则链 |
自定义 Bridge 的 DNS 工作原理:Docker 在容器内自动配置 /etc/resolv.conf 指向 127.0.0.11(Docker 内置的 DNS 代理),并维护一张"服务名→IP"的映射表。当容器解析 db 时,Docker DNS 返回 db 容器当前的 IP,即使 IP 变化也会自动更新。
4. Docker Compose 网络:多容器编排的自动组网
4.1 Compose 为你自动做了什么?
Docker Compose 的核心价值是声明式多容器编排。当你有一份 docker-compose.yml 文件并执行 docker compose up -d 时,Compose 会自动完成以下网络相关工作:
- 创建一个独立的 Bridge 网络(名字格式为
项目名_default) - 为每个服务的容器分配 IP,并注册到内置 DNS
- 注入环境变量(如
DB_HOST=db中的db就是服务名) - 按
depends_on顺序启动容器
services:
web:
build: ./web
ports:
- "8080:80"
depends_on:
- db
- redis
environment:
DB_HOST: db # db 是服务名,会被解析为 db 容器的 IP
REDIS_HOST: redis # redis 是服务名
db:
image: postgres:16
redis:
image: redis:7-alpine
在这个例子中,web 容器可以通过 db 这个名字直接连接到数据库,不需要知道具体的 IP 地址。这是通过 Compose 自动创建的 Bridge 网络中的 DNS 服务发现 实现的。
4.2 Compose 网络与默认 docker0 的本质区别
| 对比维度 | 默认 docker0 | Compose 自动网络 |
|---|---|---|
| 网络创建 | Docker 安装时自动创建 | docker compose up 时自动创建 |
| 网络名称 | docker0 |
项目名_default(如 myapp_default) |
| DNS 解析 | ❌ 不支持 | ✅ 服务名自动解析为 IP |
| 项目隔离 | 所有容器在同一网络 | 不同项目网络互相隔离 |
| 容器互通 | 用 IP 地址 | 用服务名(如 ping db) |
| 外部访问 | 必须 -p 暴露端口 |
同样用 ports 暴露 |
4.3 一个常见的坑:depends_on 不等于服务就绪
很多初学者误以为 depends_on 保证了 Web 启动时数据库已经可用了。这是错误的。depends_on 只保证容器启动顺序(先启动 db 容器进程,再启动 web 容器进程),但 db 容器启动后还需要初始化数据目录、监听端口,这可能需要几秒钟。
推荐解决方案:在应用代码中实现连接重试。Web 服务启动时,如果连接数据库失败,等待 2 秒后重试,直到成功。这比依赖容器的启动顺序更加健壮。
5. 跨主机容器通信:从单机到集群
5.1 为什么需要跨主机通信?
Docker Bridge 网络是一个单机方案——所有容器必须在同一台宿主机上才能通过 docker0 通信。但在生产环境中,一个应用通常需要部署在多台服务器上(高可用、负载分担),这就产生了跨主机通信的需求。
核心挑战:容器 A 在主机 X 上(IP: 172.17.0.2),容器 B 在主机 Y 上(IP: 172.17.0.3)。两个容器的 IP 都在 172.17.0.0/16 子网中,但主机 X 不知道 172.17.0.3 在主机 Y 上,主机 Y 也不知道 172.17.0.2 在主机 X 上。
5.2 VXLAN:把分散的容器"装"进同一个虚拟局域网
VXLAN(Virtual Extensible LAN) 是解决跨主机容器通信的主流技术。它的核心思想是隧道封装: (quant67.com)
容器A(10.0.1.2) ──► 封装成 VXLAN 包 ──► UDP 4789 ──► 宿主机网络 ──► 解封装 ──► 容器B(10.0.1.3)
主机A 跨越物理网络 主机B
具体过程:当容器 A 要给容器 B 发送数据时,主机 A 上的 VXLAN 模块会把原始以太网帧封装在一个 UDP 数据包中(目的端口 4789),通过宿主机的物理网络发送到主机 B。主机 B 收到后解封装,取出原始帧交给容器 B。
从容器 A 的视角看,它完全感知不到封装的细节——它以为自己就在一个普通的局域网里,容器 B 就在"隔壁"。
5.3 Docker Swarm Overlay 网络
Docker Swarm 模式内置了 Overlay 网络支持:
docker network create --driver overlay my-overlay-net
docker service create --network my-overlay-net --name web nginx
Swarm 的 Overlay 网络底层使用 VXLAN,自动在所有参与节点之间建立隧道,并维护一张"容器 IP → 宿主机 IP"的映射表。容器使用全局唯一的 IP 地址(不同于 Bridge 网络的 172.17.x.x,Overlay 网络通常使用 10.0.x.x),可以直接跨主机通信。
6. Kubernetes 网络:集群级网络抽象
6.1 K8s 网络模型的三大铁律
Kubernetes 对容器网络提出了三条不可协商的原则: (daily.dev)
| 原则 | 含义 |
|---|---|
| 每个 Pod 有独立 IP | Pod 是 K8s 的最小调度单位,不是容器。一个 Pod 内的所有容器共享同一个 Network Namespace 和 IP |
| 所有 Pod 可以不通过 NAT 直接互通 | Pod IP 在集群范围内全局可达,任意两个 Pod 可以直接用 IP 通信 |
| Pod 与宿主机可以直接通信 | Node 上的进程可以直接访问 Pod IP,Pod 也可以直接访问 Node IP |
K8s 自己不实现网络。它通过 CNI(Container Network Interface) 规范,把网络实现交给第三方插件(如 Calico、Flannel、Cilium)。
6.2 Pod 网络是怎么创建的?
当你创建一个 Pod 时,Kubelet 会按以下步骤配置网络:
- 创建 Pause 容器(也叫 Infra 容器):这是一个极小的容器,唯一的作用是持有 Network Namespace
- Kubelet 调用 CNI 插件:CNI 插件为 Pause 容器的 Namespace 配置网络(分配 IP、设置路由、创建 veth pair 等)
- 业务容器加入 Pause 的 Namespace:所有业务容器共享同一个 IP 和网络栈
Pod "web-xxx"
┌─────────────────────────────┐
│ Network Namespace │
│ IP: 10.244.1.5 │
│ ┌─────────┐ ┌─────────┐ │
│ │ 容器A │ │ 容器B │ │ ← 共享 eth0,localhost 互通
│ │ (nginx) │ │ (sidecar)│ │
│ └─────────┘ └─────────┘ │
│ ↑ │
│ Pause 容器 (hold ns) │
└─────────────────────────────┘
为什么需要 Pause 容器? 因为 Network Namespace 需要有一个"持有者"。如果所有业务容器都挂了,Namespace 就会消失,网络配置也就丢失了。Pause 容器什么都不做,只负责"占着"这个 Namespace,确保网络的持久性。
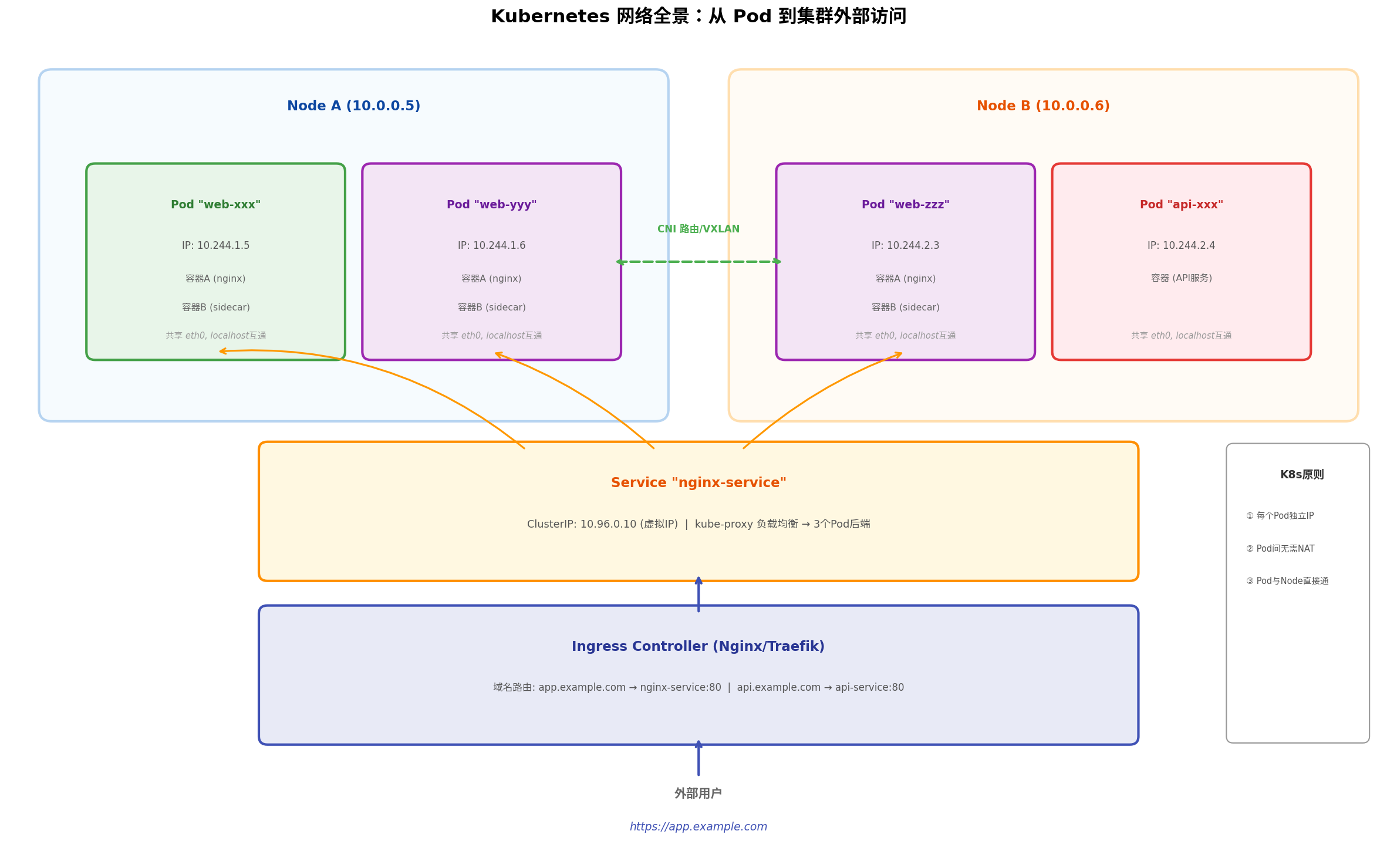
6.3 CNI 插件:Flannel vs Calico vs Cilium
CNI 插件是实现 K8s 网络的核心。三大主流插件各有侧重: (daily.dev)
| 维度 | Flannel | Calico | Cilium |
|---|---|---|---|
| 核心机制 | VXLAN Overlay(UDP 封装) | BGP 路由协议(纯三层) | eBPF(内核可编程) |
| 复杂度 | 最简单 | 中等 | 最复杂 |
| 性能 | 良好(Overlay 有约 15-20% 开销) | 最佳(接近裸机) | 极佳(eBPF 加速) |
| NetworkPolicy | ❌ 不支持 | ✅ 完整支持 | ✅ 完整支持 + L7 |
| 资源占用(每节点) | ~22 MiB | ~68-85 MiB | ~210 MiB |
| 适用场景 | 中小集群、快速上手 | 大型生产集群、安全合规 | 大规模、L7 策略、可观测性 |
Flannel 的核心代码不到一万行,只做一件事:给每个节点分配一个子网,建立 Overlay 网络让 Pod IP 跨节点可达。它配置简单、资源占用极低,但不支持 NetworkPolicy(安全策略)。 (quant67.com)
Calico 使用 BGP(边界网关协议) 在节点之间广播 Pod 路由。每个节点运行 BIRD 守护进程,通过 BGP UPDATE 把"我这个节点上有哪些 Pod IP"告诉其他节点。其他节点收到后更新自己的路由表,直接把包发给目标节点。没有封装/解封装开销,性能接近原生网络。 (quant67.com)
Cilium 基于 eBPF 技术,把网络策略和负载均衡逻辑直接编译进内核,绕过传统的 iptables/netfilter 栈。它支持 L7 级别的策略(如"只允许 GET /api/v1/users"),并提供 Hubble 流量可视化工具。
6.4 Service:解决 Pod IP 不稳定的问题
Pod 是临时的——它会因为滚动更新、节点故障、资源不足等原因被销毁重建,IP 地址也会随之变化。K8s 用 Service 提供稳定的虚拟 IP(ClusterIP)。
客户端Pod ──► 访问 nginx-service:80 ──► 实际负载到 10.244.1.5:80 或 10.244.2.3:80
│
▼
ClusterIP: 10.96.0.10 (虚拟IP,不存在真实网卡)
Service 的实现依赖于 kube-proxy,它在每个节点上维护 iptables 或 IPVS 规则:当访问 ClusterIP 时,把流量 DNAT 到某个后端 Pod 的 IP。同时,K8s 内置的 CoreDNS 会把 Service 名自动解析为 ClusterIP。 (quant67.com)
6.5 从集群外部访问:Ingress
Service 的 ClusterIP 只在集群内部可达。要从外部访问集群内的服务,有三种方式:
| 方式 | 原理 | 适用场景 |
|---|---|---|
| NodePort | 在每个节点上开一个端口(如 30080),流量通过 iptables 转发到 Service | 开发测试 |
| LoadBalancer | 云厂商集成,自动创建云负载均衡器 | 生产环境(云厂商) |
| Ingress | 用 Nginx/Traefik 做七层路由,一个 Ingress 控制器代理多个域名 | 生产环境(最常用) |
Ingress 是最推荐的生产方案。它允许你用一份 YAML 配置实现基于域名的路由:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
- host: app.example.com
http:
paths:
- path: /
backend:
service:
name: nginx-service
port: { number: 80 }
- host: api.example.com
http:
paths:
- path: /
backend:
service:
name: api-service
port: { number: 80 }
7. DNS 在容器网络中的核心作用
7.1 为什么容器网络特别需要 DNS?
在传统服务器环境中,你可以把数据库 IP 192.168.1.100 写死在应用配置里,因为这台服务器的 IP 是固定的。但在容器环境中:
- 容器每次重启都可能获得不同的 IP
- 同一服务的多个实例(如 3 个 Web 容器)有不同的 IP
- 容器可能在不同的主机之间迁移
如果代码里写死 IP,应用就会频繁断连。DNS 服务发现解决了这个问题:用名字代替 IP,由 DNS 系统负责把名字实时翻译成当前正确的 IP。
7.2 Docker 中的 DNS 工作原理
在自定义 Bridge 网络或 Compose 网络中,Docker 会在每个容器内自动配置 /etc/resolv.conf:
$ cat /etc/resolv.conf
nameserver 127.0.0.11 # ← Docker 内置 DNS 代理
options ndots:0
127.0.0.11 不是真实的独立进程,而是 Docker Daemon 内嵌的 DNS 服务。当容器里的应用请求解析 db 时: (quashbugs.com)
- 请求发送到
127.0.0.11 - Docker DNS 查询自己的"服务名→IP"映射表
- 返回
db容器当前的 IP(如172.20.0.2) - 如果
db容器重启后 IP 变了,映射表会自动更新
7.3 Kubernetes 中的 DNS:CoreDNS
K8s 集群内置 CoreDNS 作为集群 DNS 服务器。它为以下对象提供解析:
| 查询名称 | 解析结果 |
|---|---|
<service-name> |
同一 Namespace 下的 Service ClusterIP |
<service-name>.<namespace> |
跨 Namespace 的 Service ClusterIP |
<pod-ip>.<namespace>.pod.cluster.local |
Pod 的 IP(不推荐直接使用) |
例如,在 default Namespace 的 Pod 中,访问 nginx-service 会被解析为 10.96.0.10(Service 的 ClusterIP),然后 kube-proxy 负责把流量负载均衡到后端 Pod。
8. 对比总结:从 Docker 到 K8s 的网络演进
| 维度 | Docker 默认 Bridge | Docker Compose | Kubernetes + CNI |
|---|---|---|---|
| IP 归属 | 容器级 | 容器级(服务名) | Pod 级(Pause 容器持有) |
| 跨主机通信 | ❌ 不支持 | ❌ 不支持 | ✅ CNI 原生支持 |
| DNS 服务发现 | ❌ 不支持 | ✅ 服务名解析 | ✅ CoreDNS + Service 名 |
| 负载均衡 | ❌ 无原生支持 | ❌ 无原生支持 | ✅ kube-proxy(iptables/IPVS) |
| 外部访问 | -p 端口映射 |
ports 端口映射 |
NodePort / LoadBalancer / Ingress |
| 网络隔离 | 全部容器互通 | 项目级隔离 | Namespace 级 NetworkPolicy |
| 适用规模 | 单机开发 | 单机多服务 | 大规模集群生产 |
9. 附录:网络调试命令速查
9.1 Docker 网络调试
# 查看所有网络
docker network ls
# 查看某个网络的详细信息(包括容器 IP)
docker network inspect bridge
# 查看容器的 IP 地址
docker inspect <container> --format='{{.NetworkSettings.IPAddress}}'
# 进入容器测试网络
docker exec -it <container> sh
ping <another-container-ip>
# 查看宿主机上的 veth 设备
ip link show type veth
# 查看 docker0 网桥上的接口
bridge link show docker0
# 或:brctl show docker0
# 查看 Docker 插入的 iptables 规则
sudo iptables -t nat -L -n -v
sudo iptables -t filter -L -n -v
# 查看连接追踪(NAT 会话状态)
sudo conntrack -L -s 172.17.0.2
# 抓包分析
docker run --rm --net=host nicolaka/netshoot tcpdump -i docker0 -n icmp
9.2 Kubernetes 网络调试
# 查看 Pod IP
kubectl get pod -o wide
# 进入 Pod 测试网络
kubectl exec -it <pod> -- sh
ping <another-pod-ip>
# 查看 Service 详情
kubectl get svc
kubectl describe svc <service-name>
# 查看节点上的 iptables 规则(kube-proxy 生成)
sudo iptables -t nat -L KUBE-SERVICES -n -v
# 查看 CNI 配置
ls /etc/cni/net.d/
cat /etc/cni/net.d/10-*.conf
# 使用网络调试工具 Pod
kubectl run netshoot --rm -i --tty --image nicolaka/netshoot -- /bin/bash
总结
容器网络的本质是在隔离与连通之间寻找平衡:Network Namespace 提供了强隔离,veth pair 和 Linux Bridge 提供了连通,iptables NAT 提供了与外部世界的交互,DNS 服务发现提供了动态环境下的稳定寻址。
| 核心组件 | 作用 | 通俗理解 |
|---|---|---|
| Network Namespace | 网络资源隔离 | 每个容器有独立的"网络房间" |
| veth pair | 连接两个 Namespace | 虚拟网线,一端在容器,一端在宿主机 |
| Linux Bridge | 二层转发 | 软件交换机,根据 MAC 地址决定发给谁 |
| iptables NAT | 地址转换 | SNAT=“借宿主机的身份上网”,DNAT=“按门牌号找人” |
| DNS | 名字解析 | 用 db 代替 172.17.0.2,IP 变了也不怕 |
| CNI 插件 | 集群级网络 | 在多台机器之间"编织"一张统一的虚拟网络 |
从 Docker Bridge 的单机虚拟交换机,到 Kubernetes CNI 的集群级路由网络,容器网络的发展始终遵循一个原则:让应用开发者感知不到网络的存在,同时让运维工程师拥有完全的控制能力。