Docker 容器运行时深度解析:从 docker run 到内核系统调用
版本:v1.0 核心线索:以
docker run alpine echo hello为切入点,逐层拆解 Docker 从用户命令到内核系统调用的完整链路。全文围绕架构分层、镜像存储、容器生命周期、内核隔离与资源清理五大支柱展开,帮助读者建立对容器技术的系统性认知。
1. Docker 架构总览:六层调用链
1.1 容器不是虚拟机——从操作系统级虚拟化说起
Docker 的本质是一个遵循 OCI(Open Container Initiative) 标准的容器化平台。与通过硬件虚拟化技术模拟完整计算机的虚拟机(VM)不同,Docker 采用操作系统级虚拟化(OS-level virtualization):容器内的进程与宿主机共享同一个 Linux 内核,仅借助内核提供的隔离机制营造出"独立系统"的错觉。这种设计带来的好处是立竿见影的——容器可以在秒级甚至毫秒级启动,且性能损耗极低,因为不存在额外的操作系统内核和硬件抽象层。 (DEV Community)
当你执行一条看似简单的 docker run alpine echo hello 时,背后发生的是一整套精密编排:从命令行解析到 REST API 调用,从 gRPC 跨进程通信到文件系统准备,从 Namespace 创建到 Cgroup 资源限制,最终才在隔离环境中执行 /bin/echo hello。理解这条链路,是掌握云原生技术的基石。
1.2 架构六层模型
Docker 的架构经历过一次关键拆分(Docker 1.11+),从早期的单体 daemon 演进为如今的模块化分层架构:

| 层级 | 组件 | 核心职责 | 与上下层的通信方式 |
|---|---|---|---|
| 用户交互层 | Docker CLI | 解析命令行参数,发送 REST API 请求 | HTTP over UNIX Socket → dockerd |
| API 网关层 | Docker Daemon (dockerd) |
镜像/网络/卷管理,将请求翻译为 containerd 调用 | gRPC → containerd |
| 运行时管理层 | containerd | 镜像拉取、快照管理、创建 OCI Bundle、启动 shim | ttrpc/exec → containerd-shim |
| 容器守护层 | containerd-shim-runc-v2 | 每容器一个:保活、IO 转发、信号代理、状态上报 | exec + pipe → runc |
| 隔离执行层 | runc | 读取 OCI Bundle,调用 Linux 系统调用创建隔离进程 | syscalls → Linux Kernel |
| 内核能力层 | Linux Kernel | Namespace 视图隔离、Cgroup 资源限制、Seccomp 系统调用过滤 | — |
这种分层设计的根本目的在于解耦与稳定:dockerd 负责面向用户的 API 和生态工具(如 Docker Compose),containerd 负责容器生命周期管理,runc 只负责一次性的"创建隔离进程"。即使 dockerd 或 containerd 重启,已运行的容器也不会受到影响——因为每个容器都有一个独立的 shim 进程作为守护者在运行。 (DEV Community)
2. 核心组件与职责边界
2.1 Docker Daemon:从"全能管家"到"API 翻译官"
在早期版本的 Docker 中,dockerd 是一个"全能管家"——它既处理用户 API,又直接创建容器进程,还管理镜像和网络。这种单体架构虽然简单,却带来了稳定性隐患:一旦 daemon 崩溃,所有容器都会受影响。如今,dockerd 的职责被精简为面向用户的 API 服务和生态编排:它接收来自 Docker CLI 的 REST 请求,解析镜像引用、验证用户参数、合并安全配置,然后将这些请求翻译为对 containerd 的 gRPC 调用。它本身不再直接创建容器进程,而是作为 containerd 的一个高级 Client 存在。 (DEV Community)
2.2 containerd:容器运行时的"事实标准"
containerd 最初是 Docker 项目的一部分,后来被捐赠给 CNCF(云原生计算基金会),成为一个独立的开源项目。它不仅是 Docker 的核心依赖,也是 Kubernetes 默认的容器运行时接口(CRI)实现。containerd 的核心职责包括:镜像元数据管理(存储在 boltdb 中)、调用 Snapshotter 准备 rootfs、创建 OCI Bundle、启动和管理 shim 进程。 (oneuptime.com)
containerd 采用插件化架构,几乎所有核心功能都是以插件形式实现的:
| 插件类型 | 用途 |
|---|---|
| Content | 镜像层(layer)的原始内容存储 |
| Snapshotter | 文件系统分层与挂载(默认 overlayfs) |
| Runtime | 容器执行时管理 |
| Metadata | 容器与镜像的元数据持久化(BoltDB) |
| CRI | Kubernetes 集成接口 |
| Diff | 文件系统差异计算 |
当 dockerd 向 containerd 发起 Create 请求时,containerd 会依次调用上述插件完成环境准备,最终生成一个标准的 OCI Bundle。 (DEV Community)
2.3 containerd-shim-runc-v2:容器的"贴身保镖"
每个运行中的容器都对应一个 shim 进程(命名格式为 containerd-shim-runc-v2)。这个设计的精妙之处在于解耦容器进程与 containerd 的生命周期:
| 职责 | 技术实现 | 价值 |
|---|---|---|
| 保活 | shim 通过 setsid() 脱离 containerd 的进程组,成为独立守护进程 |
containerd 或 dockerd 重启/崩溃,容器不受影响 |
| IO 转发 | 持有容器的 stdin/stdout/stderr 管道,通过 gRPC 流转发 | 用户能在宿主机终端看到容器输出 |
| 状态上报 | 通过 waitpid() 捕获容器进程退出码,生成 TaskExit 事件 |
dockerd 能实时感知容器状态变化 |
| 信号代理 | docker stop 时,接收指令并向容器 PID 1 发送 SIGTERM/SIGKILL |
实现优雅停止与强制终止 |
| 资源清理 | 容器退出后,卸载 OverlayFS 挂载、删除 Cgroup 目录 | 避免资源泄漏 |
shim-v2 架构是 containerd 1.2+ 引入的重大改进。在 shim-v1 时代,shim 由 containerd 官方维护;随着运行时生态的丰富,每个 OCI 运行时(如 runc、crun、Kata)现在都实现了自己的 shim,以更好地适配特定需求。唯一仍由 containerd 官方维护的是 containerd-shim-runc-v2,因为 runc 是行业事实标准。 (DEV Community)
2.4 runc:拧螺丝的"最终执行者"
runc 是 OCI Runtime Spec 的参考实现,也是 Docker 默认的低级运行时。它的职责非常聚焦:读取 OCI Bundle 中的 config.json,调用 Linux 系统调用创建隔离进程。runc 本身不是守护进程——执行完 runc create 和 runc start 后即退出,后续由 shim 接管。这种"一次性执行"的设计让 runc 的核心代码保持在约 1.5 万行左右,极轻量且易于审计。 (DEV Community)
3. 镜像、层与 OverlayFS 存储机制
3.1 镜像的本质:分层只读文件系统
Docker 镜像不是单个文件,而是一系列**只读层(Layer)**的堆叠。以 alpine:3.19 为例,假设它由两层组成:第一层是基础系统文件(/bin、/lib、/etc),第二层是额外安装的软件包。这些层在磁盘上物理独立存储,但逻辑上通过 OverlayFS 叠加呈现为一个完整的根文件系统。 (Docker Documentation)
这种分层设计的核心优势在于共享与复用:基于同一镜像启动 100 个容器,镜像层(lowerdir)在磁盘上只有一份,100 个容器共享读取;每个容器仅有独立的可写层(upperdir),互不影响。这是 Docker 镜像轻量的根本原因。
3.2 OverlayFS 深度解析
OverlayFS 是 Linux 内核实现的联合挂载(Union Mount)文件系统,Docker 默认的存储驱动。它通过四个核心目录实现分层视图:
| 角色 | 作用 | Docker 对应 |
|---|---|---|
lowerdir |
只读层,可多层,从上到下叠加 | 镜像的各只读层 |
upperdir |
可写层,所有容器修改落在此处 | 容器的可写层(container layer) |
merged |
合并后的统一视图,容器实际看到的根目录 | 容器内的根目录 / |
workdir |
工作目录,用于原子操作和临时文件 | Docker 内部管理 |
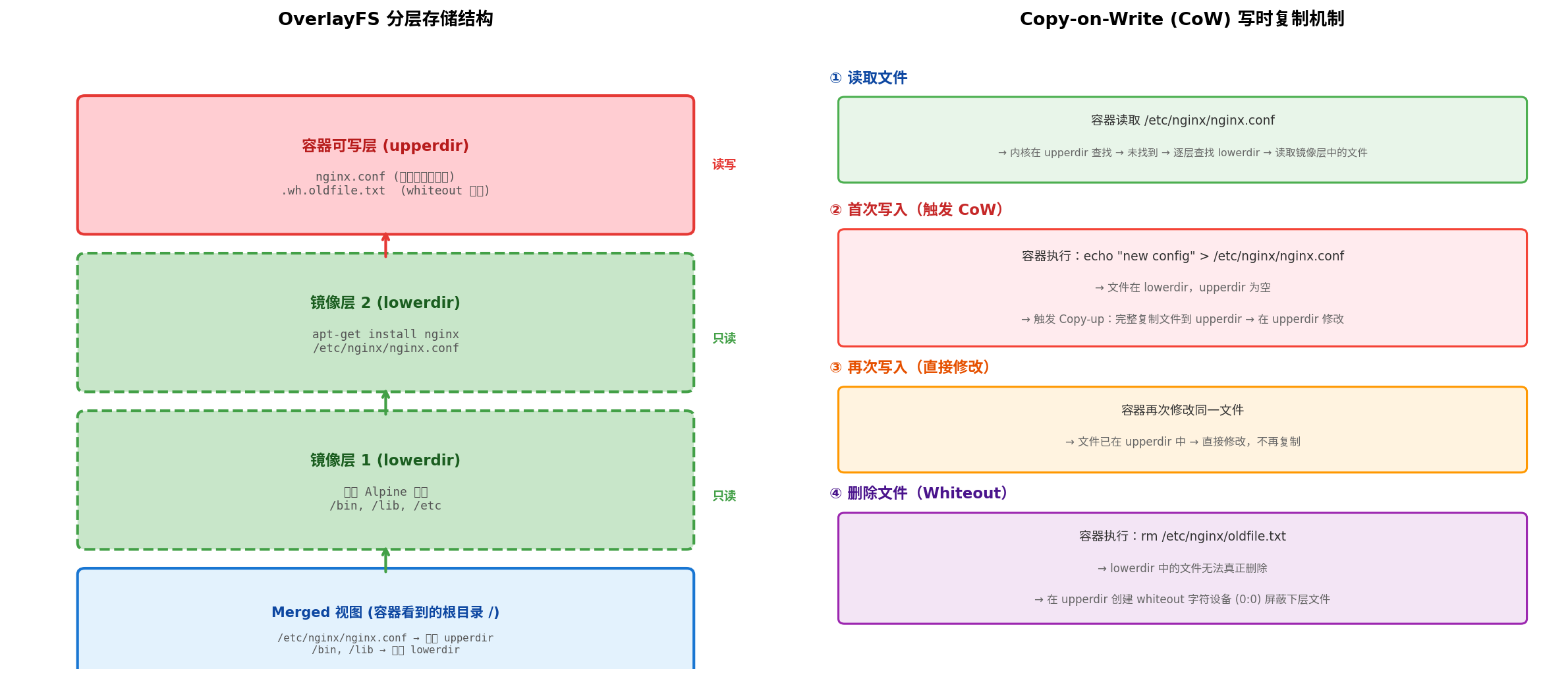
读取文件时,内核优先在 upperdir 查找;若未找到,则逐层向下查找 lowerdir。得益于内核的 Page Cache,跨层查找的性能损耗极小。首次写入时触发写时复制(Copy-on-Write, CoW):若文件存在于 lowerdir 但不在 upperdir,内核会将其完整复制到 upperdir 后再进行修改。这意味着修改大文件时会有短暂的性能开销——因此生产环境中建议将大数据放在 Volume 中,绕过 OverlayFS。 (Docker Documentation)
删除文件时,OverlayFS 使用一种巧妙的 whiteout 机制:由于 lowerdir 中的文件无法真正删除,系统会在 upperdir 创建一个同名的特殊字符设备(主/次设备号均为 0:0),标识为 c---------。这个 whiteout 文件会在 merged 视图中屏蔽下层的同名文件,让容器"看到"文件已被删除。删除目录时,则会在 upperdir 创建同名目录并设置 trusted.overlay.opaque = "y" 标记。 (oneuptime.com)
3.3 Docker 存储路径全景
理解 OverlayFS 的物理落点,对排查磁盘空间问题至关重要:
/var/lib/docker/
├── image/
│ └── overlay2/
│ ├── imagedb/ # 镜像元数据(JSON:层关系、配置、历史)
│ └── layerdb/ # 层元数据(diff 目录对应关系、父层指针)
│
├── overlay2/ # 实际文件系统层
│ ├── <layer-hash>/ # 镜像层(只读)
│ │ ├── diff/ # 该层的实际文件内容
│ │ └── link # 短名软链接,避免挂载路径过长
│ │
│ └── <container-id>/ # 容器可写层 + merged 挂载点
│ ├── diff/ # upperdir(容器所有修改的物理落点)
│ ├── merged/ # 容器根文件系统挂载点(虚拟视图)
│ ├── work/ # OverlayFS 工作目录
│ └── lower # 文本文件,记录 lowerdir 层链
│
└── containers/ # 容器配置(宿主机视角 JSON)
└── <container-id>/
└── config.v2.json
需要特别强调的是:不要手动删除 /var/lib/docker/overlay2/ 下的任何内容,这会破坏镜像和容器的完整性。正确的清理方式是使用 docker system prune 系列命令。 (mantraideas.com)
4. 容器启动完整生命周期
以 docker run alpine echo hello 为线索,以下展示从用户回车到内核系统调用的全链路。这张全景图将前文的架构组件和存储机制串联为一个有机整体。
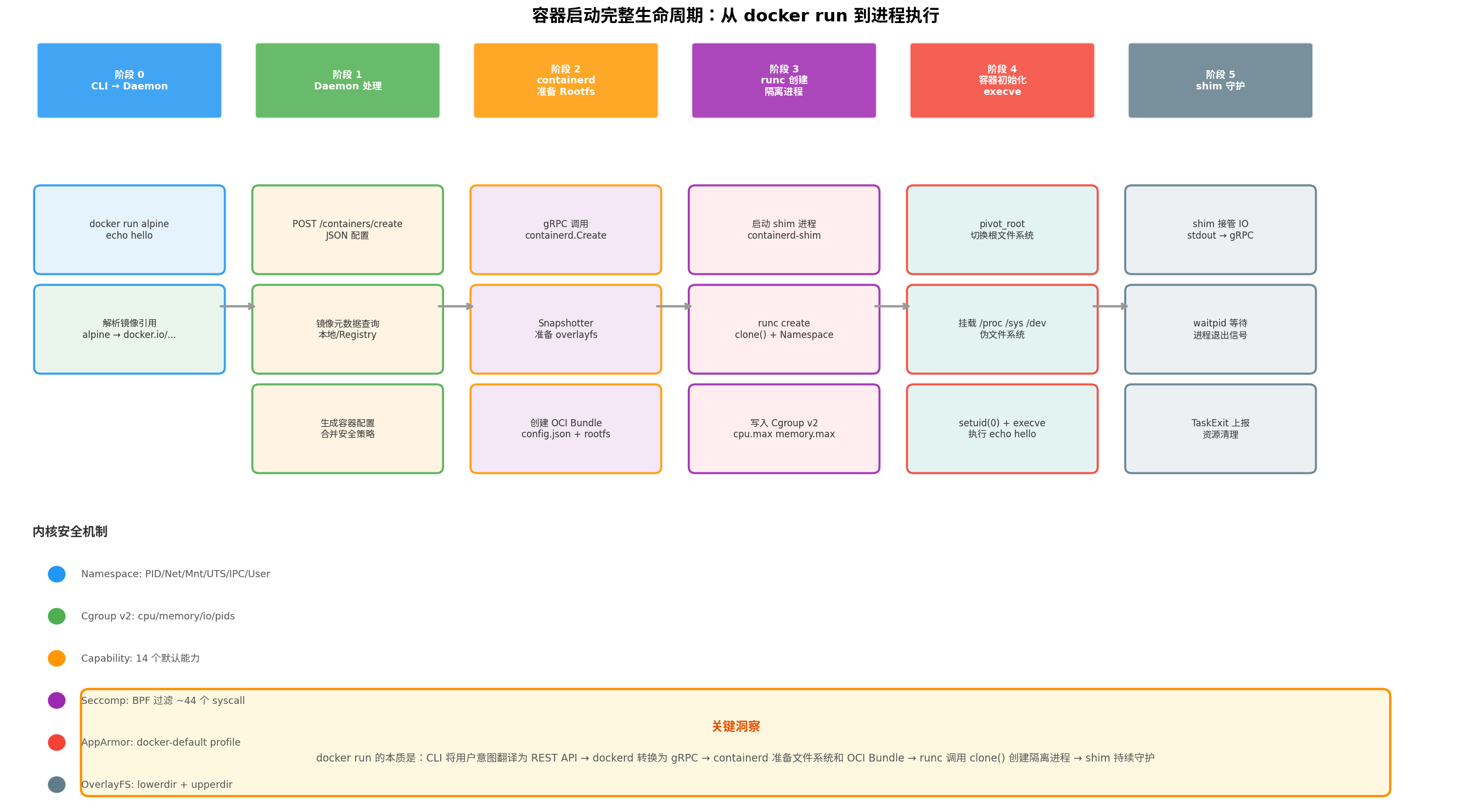
4.1 阶段 0:Docker CLI → Docker Daemon
当你在终端输入 docker run alpine echo hello 时,CLI 首先解析这条命令:将简写的镜像名 alpine 补全为完整的镜像引用 docker.io/library/alpine:latest,将 echo hello 解析为容器启动后执行的进程参数。随后,CLI 通过 UNIX Socket(/var/run/docker.sock)向 dockerd 发送 HTTP POST 请求: (DEV Community)
POST /v1.45/containers/create
Content-Type: application/json
{
"Image": "alpine",
"Cmd": ["echo", "hello"],
"HostConfig": {
"NetworkMode": "default"
}
}
docker run 在内部被拆分为两个 API 调用:/containers/create 创建配置,/containers/{id}/start 启动容器。
4.2 阶段 1:Docker Daemon 内部处理
dockerd 接收到请求后,首先将 alpine 解析为完整的镜像引用 docker.io/library/alpine:latest,然后查询本地镜像元数据(位于 /var/lib/docker/image/overlay2/imagedb/)。若本地不存在,触发 docker pull:向 Docker Hub 请求镜像的 Manifest(层清单和配置 JSON),逐层下载压缩包并解压到 /var/lib/docker/overlay2/<layer-hash>/diff/。 (DEV Community)
接下来,dockerd 将用户参数、镜像配置、默认安全策略合并为 ContainerConfig,包括:
- 进程参数:环境变量、工作目录、Entrypoint 与 Cmd 的合并结果
- 网络配置:默认 bridge 模式,分配 veth pair 和 IP 地址
- 资源限制:CPU、内存、Pids(后续写入 Cgroup)
- 安全策略:默认 14 个 Capability、Seccomp Profile、AppArmor/SELinux 标签
- 挂载配置:volumes、tmpfs、bind mounts 等
最后,dockerd 作为 containerd 的 gRPC Client,发起 CreateContainerRequest 调用。 (DEV Community)
4.3 阶段 2:containerd 与 Snapshotter(准备 Rootfs)
containerd 收到请求后,首先在内部的 boltdb 中记录容器元数据,分配容器 ID。然后调用 Snapshotter(默认 overlayfs)准备文件系统:snapshotter.Prepare(key="<container-id>", parent=alpine_top_layer) 会读取镜像的 layer 链确定 lowerdir 路径,创建新的空目录作为 upperdir,并执行 OverlayFS 挂载到 merged/ 目录。 (DEV Community)
随后,containerd 在运行时目录创建 OCI Bundle——这是 runc 启动容器的唯一输入:
/var/run/docker/containerd/.../moby/<container-id>/
├── config.json # OCI Runtime Spec:Namespace、Cgroup、Capabilities、Seccomp 等
└── rootfs/ # 符号链接 → /var/lib/docker/overlay2/<container-id>/merged/
config.json 是容器的"宪法"。以下是其中与隔离机制相关的核心片段:
{
"ociVersion": "1.1.0",
"process": {
"args": ["/bin/echo", "hello"],
"env": ["PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"]
},
"linux": {
"namespaces": [
{ "type": "pid" },
{ "type": "network" },
{ "type": "ipc" },
{ "type": "uts" },
{ "type": "mount" },
{ "type": "user" }
],
"resources": {
"cpu": { "shares": 1024 },
"memory": { "limit": 0 }
},
"capabilities": {
"bounding": ["CAP_CHOWN", "CAP_KILL", "CAP_NET_RAW", "..."]
},
"seccomp": { "defaultAction": "SCMP_ACT_ERRNO", "syscalls": [...] },
"apparmorProfile": "docker-default"
}
}
4.4 阶段 3:runc 创建隔离进程
containerd 通过 go-runc 库执行 runc,命令大致如下:
runc --root /var/run/docker/runtime-runc/moby \
create \
--bundle /var/run/docker/containerd/.../moby/<container-id> \
<container-id>
runc 的核心动作包括以下四步:
第一步:创建 Namespace 中的 init 进程。runc 调用 clone() 系统调用,同时指定多个 Namespace flags:CLONE_NEWNS(Mount)、CLONE_NEWPID(PID)、CLONE_NEWNET(Network)、CLONE_NEWIPC(IPC)、CLONE_NEWUTS(UTS)、CLONE_NEWUSER(User)。此时创建的进程还不是 /bin/echo hello,而是一个临时的 runc init 进程——它已经处于新的 Namespace 中,但仍在执行 runc 的代码,通过 socket 向父进程报告"我已就位"。 (博客园)
第二步:设置 Cgroup。runc 读取 config.json 中的 linux.resources,向宿主机的 Cgroup v2 文件系统写入配置。在 cgroup v2 统一层级下,路径为 /sys/fs/cgroup/system.slice/docker-<id>.scope/,关键文件包括 cpu.max、memory.max、pids.max。随后将 init 进程 PID 加入该 Cgroup 的 cgroup.procs。 (oneuptime.com)
第三步:设置 Capabilities。通过 prctl(PR_CAP_AMBIENT, ...) 和 capset() 系统调用设置 capability 集合。默认 Docker 容器拥有约 14 个 capability(如 CAP_CHOWN、CAP_KILL、CAP_NET_RAW),但明确移除了 CAP_SYS_ADMIN(不能随意 mount)、CAP_SYS_MODULE(不能加载内核模块)等高危权限。 (quant67.com)
第四步:加载 Seccomp。runc 通过 prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, ...) 加载 BPF 过滤器。Docker 默认 Profile 禁止约 44 个危险系统调用,包括 reboot(防止重启宿主机)、mount/umount2(防止文件系统逃逸)、open_by_handle_at(历史漏洞相关)、ptrace(防止调试攻击)。 (rahalkar.dev)
4.5 阶段 4:容器初始化与用户命令执行
当 containerd 调用 runc start <container-id> 后,处于新 Namespace 中的 runc init 进程继续执行初始化:
pivot_root 切换根文件系统。这是容器化的关键一步——将 OverlayFS 的 merged/ 目录变成新的根目录 /,同时将旧的宿主机根文件系统移到 /.old_root 并卸载隐藏。从此,容器内的进程再也无法直接访问宿主机的根文件系统。 (Github)
挂载伪文件系统。根据 config.json 的 mounts 配置,依次挂载 /proc(procfs)、/sys(sysfs,只读)、/dev(tmpfs)、/dev/pts(devpts)等。独立的 /proc 至关重要,因为 PID Namespace 需要展示容器内独立的进程树。 (Github)
设置用户身份。在 User Namespace 的保护下,容器内执行 setuid(0) 和 setgid(0)。表面上是 root,但由于 UID 映射机制,这个"root"在宿主机上只是一个非特权用户(如 /etc/subuid 中定义的 165536)。即使容器进程逃逸出 Namespace,也无法危害宿主机。 (CSDN博客)
execve 执行用户命令。最终一步——进程替换:execve("/bin/echo", ["/bin/echo", "hello"], envp)。runc init 的代码被完全替换为 /bin/echo,容器内 PID 1 现在是 echo hello。
4.6 阶段 5:shim 持续守护
在 runc 退出后,containerd-shim-runc-v2 成为容器进程的父进程。它的核心职责是持续守护:通过 waitpid() 等待容器进程退出、通过 gRPC 流将 stdout/stderr 转发给 containerd、在 docker stop 时接收指令并向容器 PID 1 发送 SIGTERM(默认 10 秒后 SIGKILL)。当容器最终退出时,shim 负责清理 Cgroup 目录、卸载 OverlayFS、上报 TaskExit 事件,然后自身退出。 (DEV Community)
5. 内核隔离机制详解
容器之所以能够实现隔离,根本原因在于 Linux 内核提供的五大机制。它们协同工作,从"看得见"到"用得了"再到"调得着",层层设防。
5.1 Namespace:视图隔离(让进程"看不见")
Namespace 解决的是可见性问题——让每个容器进程只能看到部分系统资源,产生"独占整个系统"的错觉。Docker 默认使用 6 种 Namespace: (oneuptime.com)
| Namespace | 隔离内容 | 容器内的错觉 | 对应 clone() flag |
|---|---|---|---|
| PID | 进程 ID 空间 | ps 只看到自己和少量进程,PID 从 1 开始 |
CLONE_NEWPID |
| Network | 网络设备、端口、路由 | 以为自己有独立网卡、IP,端口从 1 起可用 | CLONE_NEWNET |
| Mount | 文件系统挂载点 | 以为 / 就是根,看不到宿主的 /home |
CLONE_NEWNS |
| UTS | 主机名/域名 | hostname 显示容器自己的名称 |
CLONE_NEWUTS |
| IPC | 共享内存、信号量、消息队列 | 与宿主和其他容器完全隔离 | CLONE_NEWIPC |
| User | 用户/组 ID | 容器内 root(UID 0)映射为宿主机普通用户 | CLONE_NEWUSER |
关键认知:Namespace 只隔离视图,不隔离物理资源。容器内的 PID 1 在宿主机内核调度器看来,只是一个普通的 PID(如 5678)。你可以通过 ls /proc/<container-pid>/ns/ 查看一个容器的所有 Namespace 文件。 (oneuptime.com)
5.2 Cgroup:资源限制(让进程"用不了")
如果说 Namespace 是"看不见",Cgroup 就是"用不了"。它限制进程组对 CPU、内存、IO 等物理资源的实际使用量。现代 Linux 系统已全面转向 cgroup v2(从 Linux 4.5 引入,Linux 5.8+ 成熟),Docker 新版本也默认使用 v2。 (oneuptime.com)
cgroup v1 与 v2 的核心差异:
| 特性 | cgroup v1 | cgroup v2(主流) |
|---|---|---|
| 层级结构 | 每个控制器独立挂载(多棵树) | 统一单根树,所有控制器集中管理 |
| CPU 限制文件 | cpu.cfs_quota_us、cpu.shares |
cpu.max(配额+周期) |
| 内存限制文件 | memory.limit_in_bytes |
memory.max |
| 内存压力感知 | 不支持 | 支持 memory.pressure(PSI) |
| Swap 管理 | 可选且常禁用 | memory.swap.max 原生支持 |
| IO 控制 | blkio 控制器(老旧) |
io 控制器(支持现代 NVMe) |
| 进程放置 | 父子 cgroup 可混放进程 | 只允许叶子节点运行进程 |
在 cgroup v2 下,Docker 容器的资源限制文件统一位于 /sys/fs/cgroup/system.slice/docker-<container-id>.scope/ 目录下。例如:
# 查看容器的 CPU 和内存限制
cat /sys/fs/cgroup/system.slice/docker-<id>.scope/cpu.max
cat /sys/fs/cgroup/system.slice/docker-<id>.scope/memory.max
cat /sys/fs/cgroup/system.slice/docker-<id>.scope/pids.max
cgroup v2 的统一层级设计解决了 v1 时代的诸多痛点:不再存在多个挂载点冲突的问题,资源策略可以集中管理,且支持 PSI(Pressure Stall Information)机制,能够在内存压力达到临界点前提前预警。 (k8wiz)
5.3 Capability:精细化权限(把 root 的权力"切成碎片")
传统 Linux 中,root 用户拥有一切权力。Capability 机制将 root 的权力拆分为约 40 个独立的"碎片",每个 capability 控制一类特权操作。Docker 默认只授予容器 14 个 capability,其余全部移除: (quant67.com)
默认保留的 14 个 capability:
| Capability | 权限说明 | 典型使用场景 |
|---|---|---|
CAP_CHOWN |
修改文件所有者 | 服务启动时调整文件权限 |
CAP_KILL |
向任意进程发送信号 | 进程管理、优雅重启 |
CAP_NET_RAW |
使用原始套接字 | ping、网络诊断工具 |
CAP_NET_BIND_SERVICE |
绑定 1024 以下端口 | Web 服务器绑定 80/443 |
CAP_SETUID / CAP_SETGID |
切换用户/组 ID | 服务降权运行 |
CAP_SYS_CHROOT |
使用 chroot() |
文件系统隔离 |
CAP_MKNOD |
创建设备文件 | 特殊设备节点创建 |
CAP_AUDIT_WRITE |
写入审计日志 | 安全审计 |
默认移除的关键 capability(高危):
| Capability | 风险等级 | 说明 |
|---|---|---|
CAP_SYS_ADMIN |
极高 | 可 mount 文件系统、执行特权操作,是容器逃逸的主要途径 |
CAP_SYS_MODULE |
极高 | 可加载内核模块,直接控制宿主机 |
CAP_SYS_PTRACE |
高 | 可调试其他进程,能注入代码到同主机其他容器 |
CAP_NET_ADMIN |
高 | 可修改网络接口、路由、防火墙规则 |
生产环境最佳实践是先全部丢弃,再按需添加:docker run --cap-drop=ALL --cap-add=NET_BIND_SERVICE nginx。 (byte-guard)
5.4 Seccomp:系统调用过滤(在内核门口"安检")
Seccomp(Secure Computing Mode)通过 BPF(Berkeley Packet Filter) 程序在每个系统调用入口执行"安检"。Docker 默认启用的 Seccomp Profile 是一个白名单策略——只允许约 260 个常见系统调用通过,明确禁止约 44 个危险调用: (rahalkar.dev)
| 被禁用的系统调用类别 | 代表调用 | 禁止原因 |
|---|---|---|
| 内核管理 | reboot、kexec_load |
防止重启宿主机 |
| 文件系统操作 | mount、umount2、pivot_root |
防止文件系统逃逸 |
| 内核模块 | init_module、finit_module |
防止加载恶意模块 |
| 调试攻击 | ptrace、process_vm_readv |
防止内存注入和信息窃取 |
| eBPF | bpf |
防止内核 instrumentation |
| 设备访问 | ioperm、iopl |
防止直接硬件访问 |
| 历史漏洞 | open_by_handle_at |
CVE-2014-9356 相关 |
Seccomp 的性能开销极低:在典型的 Web 服务器场景(~10 万次系统调用/秒)下,Docker 默认 Profile 仅增加约 1-2% 的 CPU 开销。 (quant67.com) 用户可以通过 --security-opt seccomp=unconfined 关闭 Seccomp,但这在生产环境中极其危险——历史上大量容器逃逸事件都与此配置有关。 (rahalkar.dev)
5.5 AppArmor / SELinux:强制访问控制(“最后一道防线”)
AppArmor 和 SELinux 是 Linux 的强制访问控制(MAC)机制,作为 Namespace、Cgroup、Capability、Seccomp 之后的最后一道防线。
AppArmor(Ubuntu/Debian 默认)基于路径进行访问控制。Docker 的 docker-default profile 是一个中等保护强度的策略:它默认允许网络访问、文件读写和 capability 使用,但明确 deny mount、限制对 /proc 和 /sys 的写入、限制 ptrace 的使用。一个有趣的案例:即使容器拥有 CAP_SYS_ADMIN capability 且 Seccomp 被关闭,AppArmor 仍能阻止 mount --bind 操作——这充分说明了多层防御的价值。 (gitlab.io)
SELinux(RHEL/Fedora 默认)基于标签(Label)进行访问控制。容器进程和文件都被打上安全标签(如 system_u:system_r:svirt_lxc_net_t:s0:c1,c2),通过类型强制(TE)策略限制它们能访问的资源。
6. 容器退出与资源清理
6.1 正常退出流程
当容器内的 echo hello 执行完毕,进程调用 exit(0) 退出时,以下清理流程自动触发:
容器进程 exit(0)
↓
shim 的 waitpid() 捕获退出码
↓
shim 发送 TaskExit 事件 → containerd
↓
containerd 通知 dockerd,容器状态变为 "exited"
↓
shim 清理 Cgroup 目录、卸载 OverlayFS
↓
shim 自身退出
值得注意的是,容器的可写层(upperdir)默认会被保留。这意味着你可以通过 docker start 重新启动容器,之前的数据不会丢失。只有执行 docker rm 时,upperdir 和整个 overlay2 容器目录才会被物理删除。 (oneuptime.com)
6.2 强制停止(docker stop)
docker stop 的默认行为是先礼后兵:
- dockerd → containerd → shim:发送停止请求
- shim 向容器 PID 1 发送 SIGTERM(优雅终止信号)
- 等待 grace period(默认 10 秒)
- 若进程仍在运行,发送 SIGKILL(不可捕获,强制终止)
可以通过 --time 参数调整等待时间:docker stop --time=30 <container-id>。 (oneuptime.com)
6.3 数据持久化边界
| 存储位置 | 随容器删除而丢失? | 说明 |
|---|---|---|
| 容器可写层(upperdir) | docker rm 时丢失 |
docker stop/start 保留 |
| Named Volume | 否 | docker volume create,宿主机独立目录 |
| Bind Mount | 否 | 挂载宿主机已有目录 |
| tmpfs 挂载 | 是 | 内存文件系统,容器停止即消失 |
7. 附录:关键路径与调试命令
7.1 关键宿主机路径速查
| 路径 | 内容 |
|---|---|
/var/lib/docker/overlay2/<layer-hash>/diff/ |
镜像层物理文件 |
/var/lib/docker/overlay2/<container-id>/diff/ |
容器可写层(upperdir) |
/var/lib/docker/overlay2/<container-id>/merged/ |
容器根文件系统挂载点 |
/var/lib/docker/image/overlay2/imagedb/ |
镜像元数据 JSON |
/var/run/docker/containerd/.../moby/<id>/ |
OCI Bundle(config.json + rootfs) |
/sys/fs/cgroup/system.slice/docker-<id>.scope/ |
cgroup v2 资源限制目录 |
7.2 实用调试命令
# 查看容器存储驱动信息
docker inspect <id> --format='{{.GraphDriver.Data}}'
# 查看容器在宿主机上的真实进程 ID
docker inspect <id> --format='{{.State.Pid}}'
# 查看进程的 Namespace
cat /proc/<pid>/ns/*
# 查看进程的 Cgroup 归属(cgroup v2)
cat /proc/<pid>/cgroup
# 查看进程的 Capability
cat /proc/<pid>/status | grep Cap
capsh --decode=$(cat /proc/<pid>/status | grep CapEff | awk '{print $2}')
# 查看 OverlayFS 挂载详情
mount | grep overlay | grep <container-id>
# 查看 AppArmor 配置
docker inspect <id> --format='{{.AppArmorProfile}}'
# 查看 Seccomp 状态
docker inspect <id> --format='{{.HostConfig.SecurityOpt}}'
# 进入容器的 Namespace(调试神器)
sudo nsenter --target $(docker inspect <id> --format='{{.State.Pid}}') --mount --uts --ipc --net --pid /bin/sh
总结
Docker 容器不是虚拟机,也不是魔法。它是 Linux 内核提供的 Namespace、Cgroup、Capability、Seccomp、LSM 等机制的工程化封装。一次 docker run 的背后,是 Docker CLI → dockerd → containerd → containerd-shim → runc → Linux 内核 的精密协作。
| 内核机制 | 解决的问题 | 通俗理解 |
|---|---|---|
| Namespace | 视图隔离 | “看不见"其他进程和资源 |
| Cgroup v2 | 资源限制 | “用不了"超过配额的资源 |
| Capability | 权限细分 | root 的权力被"切成碎片” |
| Seccomp | 系统调用过滤 | 危险操作在内核门口被"安检拦截” |
| AppArmor | 强制访问控制 | 即使突破前面防线,仍有"最后一道关卡" |
runc 是那个最终"拧螺丝"的工人,而 containerd-shim 是确保"工厂断电后机器仍能运转"的守护者。理解这条链路,你就掌握了云原生技术的底层逻辑。